newline
Table of Contents
TIL: uBlock Origin supports XPath syntax!
TILAugust 17, 2021
If you’re using an adblocker, chances are you’re using uBlock Origin. And if you’re not, you should be using it. Anyway, I just found out that uBlock supports XPath syntax, and here’s how to use it to hide elements on a page.
Overview
XPath is a query language for XML documents, such as an HTML page.
So basically it’s what you use to ‘select’ specific elements, just like you would use document.getElementById() (or, more generally, document.querySelector()) in JavaScript.
Personally, I prefer XPath over CSS selectors, because it feels easier to write and more flexible (not necessarily true, but it’s my subjective opinion).
It’s useful when parsing/filtering HTML, but also when writing element hiding rules for an adblocker, as I found out today.
All you need to do is add a static cosmetic filter, via the “my filters” tab in uBlock. The syntax is:
<domains>##<subject>:xpath(<expression>)Where:
<domains>is a comma-separated list of domains on which the filter will work##means to hide elements (see here)<subject>is the root element to which the XPath expression will be applied; can be a CSS selector or a procedural cosmetic filter (see here for more info)<expression>is an XPath expression, see e.g. here for a tutorial
You can also test it out visually via uBlock’s element picker, in which case you can leave out the <domains> part of the filter.
Example
For example, let’s say I search Google for ‘apples’, and I want to block the whole ‘top stories’ section on the results page. Looking at the source code, Google obfuscates and/or randomizes many class names and IDs, but the section is a div that contains the element g-section-with-header. So to block the whole thing, I need to block any div, inside the div with ID search, which has g-section-with-header as a child.
In uBlock syntax with XPath:
google.com##div#search:xpath(//div[child::g-section-with-header])What it means:
google.com: the domain on which this filter will work##: cosmetic filterdiv#search: the root element from which XPath will start:xpath(<expression>): use XPath syntax to select an element//div[child::g-section-with-header]: looking at all descendants of the root node (div#search), selectdivelements which have as a directchildthe elementg-section-with-header
And sure enough, that makes the ‘top stories’ BS disappear.
Of course, don’t use Google, use Searx or DuckDuckGo.
Example 2
On Samsung Food, if you stay on a page for a few seconds and/or scroll around, eventually you’ll get this annoying modal that login-walls the site:
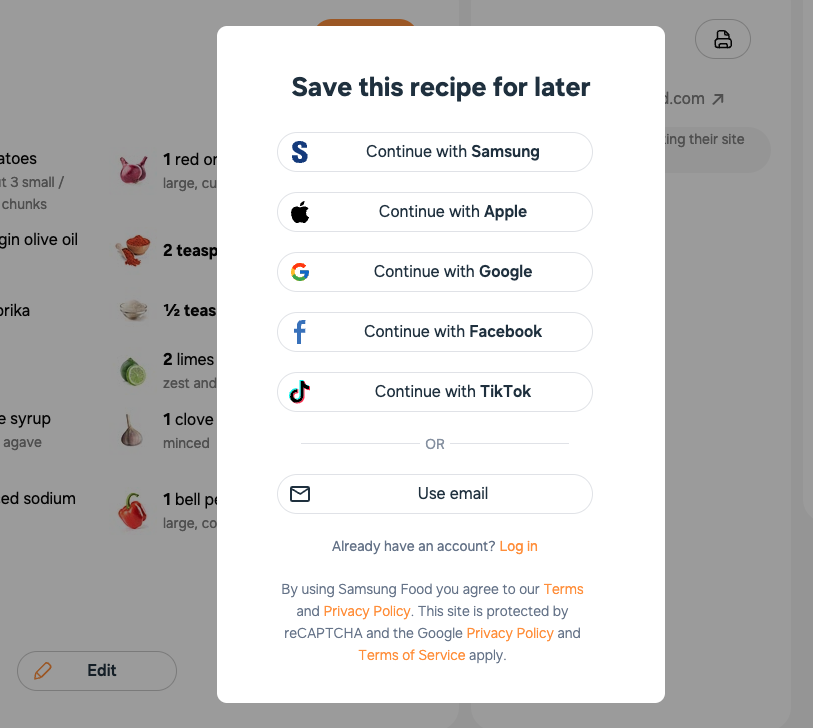
Upon inspection, turns out Samsung uses auto-generated class names and stuff like that: s95-171, s46169.
This just makes me want to get around it even more.
Looking at the page and its structure, all of the BS is contained within a div (the highlighted one):
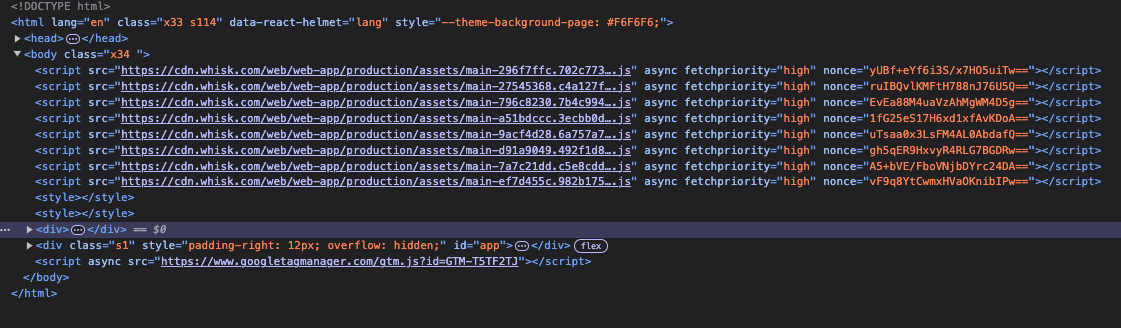
What we want is to grab a div under the body, where at least one of the div’s descendants contains the phrase “Continue with “.
This translates to an XPath filter:
app.samsungfood.com##body:xpath('div[descendant::span[contains(., "Continue with")]]')This means:
app.samsungfood.com: the page where it should be applied##: cosmetic filterbody: start at the body:xpath(<expression>): use XPath syntax to select an elementdiv[descendant::span[contains(., "Continue with ")]]': selectdivelements where at least one of thediv’s descendants contains the character string “Continue with “.
Now of course, because they’re assholes, they disable scrolling with the good old overflow: hidden trick, so we just have to fix that:
app.samsungfood.com##body:style(overflow: auto !important)And this means:
app.samsungfood.com: the page where it should be applied##: cosmetic filterbody: start at the body element:style(<expression>): change the CSS style of the elementoverflow: auto !important: allow text to overflow your view of the page, letting you scroll to see more content, and make it override all other style rules
I love hostile web design…