newline
Table of Contents
Creating a custom RSS feed for a web page with RSS-Bridge
ProgrammingSeptember 29, 2024
RSS-Bridge is a way to create an RSS feed for a web page that doesn’t provide one. Unfortunately, this is increasingly more common, as publishers prefer you go to their website so they can serve you ads and track your activity, or they want your email so they can spam your inbox and/or sell your info. RSS-Bridge is essentially a framework to generate an RSS feed for any web page, to ‘bridge’ the web with RSS. Here’s how you can use it to create a new RSS feed.
I’m assuming you’re familiar with HTML, CSS, and web scraping techniques, like selecting and filtering HTML elements by tag name, attributes, etc. If you don’t know this, it’s not absolutely necessary unless you want to adapt these instructions for a different website, but it might be worth reading up on that.
The setup
Here’s my goal: I want to have an RSS feed that lets me know what new films are available to watch in my local cinemas whenever the list changes. Of course, the website doesn’t offer one, but we can create one with RSS-Bridge. The best way to develop feeds is to self-host an instance of RSS-Bridge; I’m using the one I host on my VPS, but you can also run it locally. Just follow the instructions. It might also be useful for you to enable debug mode.
Once you have it running, switch to the RSS-Bridge repo’s root directory, and create the file bridges/PatheBridge.php:
<?php
class PatheBridge extends BridgeAbstract
{
const NAME = 'Pathe Current Films';
const URI = 'https://en.pathe.nl';
const DESCRIPTION = 'Returns films currently in the cinemas';
const MAINTAINER = 'thezeroalpha'; // This is me
const PARAMETERS = []; // Bridge takes no extra parameters
// And this will populate the feed (eventually)
public function collectData() {
}
}The naming convention is important: by ending the name with “Bridge”, RSS-Bridge knows that this file defines a bridge.
Here, we define the basic skeleton you need for a bridge: some metadata, which will show up on the main page, and the public function collectData.
This function is the core of the bridge: it takes no arguments and returns nothing, but as a side-effect, it will eventually modify the variable $this->items, which defines the list of items in the feed.
This communication is defined in the parent class BridgeAbstract, which we are extending.
Add the bridge to whitelist.txt in the root of the repo:
PatheThen reload the main RSS-Bridge page, and you should see the bridge listed on the page:

By clicking on “show more” and then “generate feed”, you’ll be able to generate an RSS feed, but as we haven’t defined any items yet, it’s empty.
Let’s create a dummy item, just to make sure it works:
<?php
// .. rest of the file as shown above ..
public function collectData() {
$this->items = [
[
'uri' => 'https://example.com',
'title' => 'Example item',
'timestamp' => '29-09-2024',
'author' => 'Example',
'content' => '<b>This is just example text.</br>',
]
];
}$this->items is an indexed array, which contains an associative array of items (the list of item parameters you can use is here).
OK, reload the generated feed, and you’ll see this:

Cool, and now comes the real work of figuring out how to convert the contents of the web page into RSS items.
The website-specific implementation
Every website shows its contents a bit differently, so you need to do some inspecting and debugging via browser dev tools. You have to figure out how to take the contents that the page gives you, and map them to the properties of a feed item.
For Pathe, I found that:
-
I can get the full HTML with a GET request, no JS is required (thankfully, otherwise I’d need to use a WebDriver, which is possible but more complex). RSS-Bridge recommends you test the site before implementing a bridge (you can do it with
curltoo). -
The results are paginated, by appending
?page=N(withNthe page number) to the URL -
Each film has an associated HTML tree, with these contents:
<a href="#" onclick="GtmClickSelectItem('{"item_id":"26344","item_name":"Interstellar (10th Anniversary)","index":0,"item_brand":"Pathe","item_category":"Avontuur,Science Fiction","item_category2":"2D,IMAX","item_category3":"","item_category4":"classics","item_category5":"","item_list_id":null,"item_list_name":null}', '/film/26344/interstellar-10th-anniversary','filmspagina')" class="poster poster--smaller" data-gtmclick="26344" title="Interstellar (10th Anniversary)"> <div class="poster__image"> <img src="https://media.pathe.nl/nocropthumb/180x254/gfx_content/posters/interstellarmainposter3c.jpg" alt="Interstellar (10th Anniversary)" onerror="this.src = '/assets/img/placeholder/poster_missing.png';"> </div> <div class="poster__footer"> <p class="poster__label">Interstellar (10th Anniversary)</p> </div> </a>
This actually give me all the information I need: some metadata is in HTML, and the rest is contained in the onclick attribute of each <a> element.
Also, the HTML is predictable – no crazy auto-generated obfuscated ID or class names, which a lot of websites also seem to love (spoiler alert - it does next to nothing, the website is still scrapeable even with those stupid class names).
So I need to:
- get the HTML for each page; RSS-Bridge provides the
getSimpleHTMLDOMCachedhelper function for that - extract the required information; RSS-Bridge uses the
simple_html_domparser, so I can use itsfind()functionality to select elements by CSS (likequerySelectorin JS) - extract the JSON (I can use a
preg_matchcall in PHP to extract with a regular expression match), replace the"entities (with PHP’sstr_replace), and parse the JSON (RSS-Bridge has a helper functionJson::decodethat I can use)
I frequently used $this->logger->debug("Some message", $some_variable) to print information to the log (if you’re running this via nginx, it’s in /var/log/nginx/error.log).
In the end, here’s what I came up with (I’m not a PHP expert so there’s probably some improvements I could make):
<?php
// .. rest of the file as shown above ..
public function collectData() {
// Cache URI data for one day
$ONE_DAY = 86400;
// Start from the first page
$page = 1;
// Base URI, defined as the constant "URI" earlier in the file
$baseURI = $this->getURI();
// Get the first page
$pageUri = $baseURI . '/films/actueel?page=' . $page;
$html = getSimpleHTMLDOMCached($pageUri, $ONE_DAY);
// Try to find the list of films on the first page; fail if none could be found
$articles = $html->find('body div.poster-list > a.poster')
or returnServerError('Could not find articles for: '. $pageUri);
// And try to look at the other pages
while (true) {
$pageUri = $baseURI . '/films/actueel?page=' . ++$page;
$html = getSimpleHTMLDOMCached($pageUri, $ONE_DAY);
// If there are no articles on this page, we probably reached the end
if (!($newArticles = $html->find('a.poster'))) {
break;
}
// Otherwise add them to the article list
$articles = array_merge($articles, $newArticles);
}
// For each movie (feed article)
foreach ($articles as $article) {
// Extract the JSON from the onclick attribute (first parameter in the
// GtmClickSelectItem function call) and the film link (second parameter).
// Place the result in `$matches`
preg_match('/GtmClickSelectItem\(\'({[^\']+)\', ?\'([^\']+)\'/', $article->onclick, $matches);
// Parse the JSON
$articleJSON = str_replace('"', '"', $matches[1]);
$articleData = Json::decode($articleJSON);
// Extract the link to the film's page
$articlePath = $matches[2];
// Extract the article image (the `0` means to return the first element)
$articleImage = $article->find('img', 0);
// Create the feed item for this movie
$item = array();
$item['title'] = $article->find('p.poster__label', 0)->plaintext;
$item['enclosures'] = [$articleImage->src];
$item['uri'] = $baseURI . $articlePath;
// Use a heredoc to create the HTML contents, since that's easier with multiline stuff.
// I add a custom link to open a page with showtimes for my selected cinemas.
$item['content'] = <<<EOF
<p><b>Film type:</b> {$articleData['item_category']}</p>
<p><b>Playing in:</b> {$articleData['item_category2']}</p>
<p><b><a href="{$baseURI}{$articlePath}">Check cinemas</a></b></p>;
$articleImage
EOF;
// Append the newly created item
$this->items[] = $item;
}
}This creates a feed of all the films on that page:
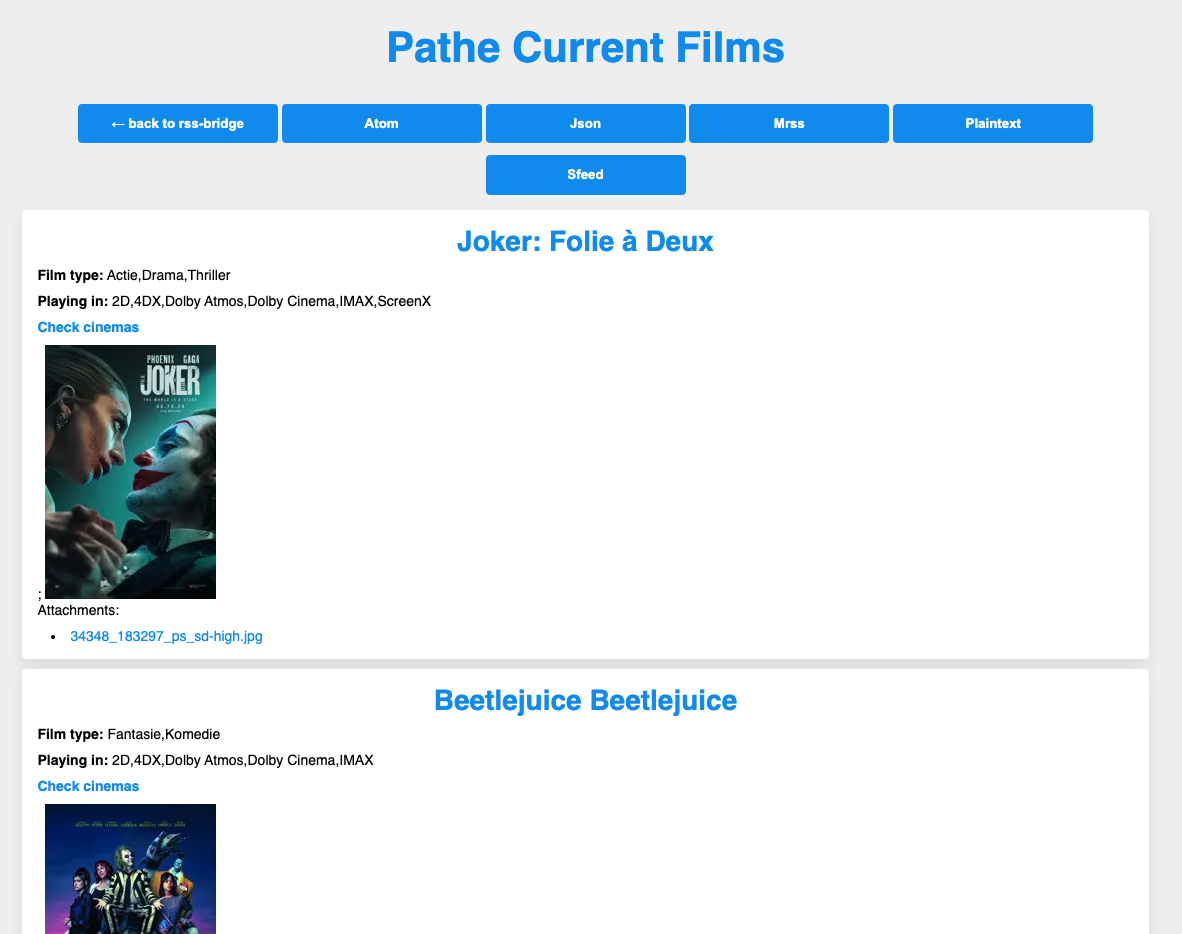
The conclusion
And that’s it, we’ve built an RSS feed generator for a website that didn’t support it natively. Another nice thing is, RSS-Bridge automatically gives me feeds in other formats: by clicking the Atom button, I get the feed in Atom format (similar to RSS), which I can add to my feed reader. But I can also see it as an HTML page (like in the screenshot above), or as JSON, without any other changes. Quite straightforward, and now I can easily know when new films are playing without having to check the website manually.